
Trend 1 – “AI-First” vs “User-First”
Bu ara konferanslarda, atölye çalışmalarında, eğitimlerde bana en çok sorulardan bir tanesi “Hocam, hangisi daha öncelikli; AI-First mü yoksa User-First mü?” sorusu. Yaşadığımız AI çağında bu soruyla karşılaşmamız çok doğal. Soruyu cevaplamadan önce soruyu doğru zemine oturmakta fayda var.
Şöyle ki: sorunun zeminine baktığımız zaman acaba “business” açıdan mı yoksa “system” açısından mı soru sorulmakta. Eğer ki soru “business” zeminindeyse cevap “User-First” yok eğer “system” bakış açısıysa cevabımız “AI-First” olacaktır. Herhangi bir zemine oturtmadan “Hangi taraftan başlamamız gerekir?” şeklinde bir soruysa tabi ki işe, analize “business” ve “user” tarafından başlayıp daha sonra bunun “system” tarafındaki iz düşümüne bakmamız gerekmektedir.
“User-First” sorusunun cevabını “iş analizi teknikleri” verecekken, “AI-First” sorusunun cevabını “sistem analizi teknikleri” verecektir.
Hemen akabinde gelen soru ise “Tamam, sistem tarafında AI-First yaklaşımıyla başlayacağız ama hangi kullanım senaryolarını AI’a devretmekle başlamalıyız?” şeklinde olmaktadır. Bunu belirlerken iki kritere dikkat etmemiz gerekmektedir:
- Kullanım Senaryosunun Frekansı (Use Case Frequency)
- Kullanım Senaryosunun Otonomisi (Use Case Autonomy)
Frekans
Otomasyon kararı verirken en çok kullandığımız kriterlerden bir tanesi kullanım senaryosunun ne kadar tekrarlandığı ile ilgilidir. Eğer çok sık tekrar eden bir kullanım senaryosu ise otomasyona adaydır, aksi takdirde çok az tekrar eden bir kullanım senaryosunu “manual” bir şekilde yapmaya devam etmek daha anlamlı ve verimli olacaktır.
Benzer durum AI’a devredeceğimiz kullanım senaryoları için de geçerlidir. Kullanım senaryosu ne kadar sıklıkla yapılıyorsa o kadar AI tarafından yapılması anlamlı ve verimli olacaktır.
Otonomi
Yalnız burada frekans ile birlikte dikkat etmemiz gereken bir kriterde AI’a devredilecek kullanım senaryosunun otonomi ihtiyacı olacaktır. Bu şu anlama gelmektedir; kullanım senaryosunda ne kadar fazla karar noktası varsa, karar alınması gerekiyorsa bu, o senaryonun o kadar AI’ya uygun olduğu anlamına gelmektedir. Her iki kriteri ele aldığımızda aşağıdakine benzer bir MoSCoW analizi karşımıza çıkmaktadır:

MoSCoW Analysis – Must, Should, Could, Won’t
Bu analize göre “Must” alanlara düşen kullanım senaryolarından başlayıp ardından “Should” ve “Could” alanlarına düşenler daha detaylı incelenerek kullanım senaryolarından hangilerinin AI’a devredileceği belirlenmelidir. “Won’t” kısmı ise AI’a devredilmesi uygun olmayan kullanım senaryolarını bize göstermektedir.
“Frekansı” ve “otonomisi” yüksek olan kullanım senaryolarından başlayarak yapay zekayı devreye almaya başlayın!
Vaka Analizi
Yukarıda ele aldığımız kriterleri özetleyecek güzel bir vaka analizinden bahsetmek istiyorum: Düşünün kurumsal bir şirketin açtığı pozisyonlara her ay 4.000 ila 5.000 arasında aday kendi formatlarında hazırladıkları özgeçmişlerle başvuruyor.
Bir form aracılığıyla şirketin web sitesine yüklenen özgeçmişlerin her birinin ayrı bir formatta olduğunu, kimi özgeçmişin en üst kısmında “kişisel bilgiler” yer alırken kimisinin “iş deneyimle” kimisinin ise “öğrenim bilgileriyle” başladığını düşünün.
Hatta kısaltmaların bile farklı anlamlar ifade edebileceğini; özgeçmişinde “ANT” yazan birisinin “Antep” başka birisinin ise “Antalya”; “İST” yazan birisinin “İstanbul” başka birisinin ise “İstinye”yi kast edebileceğini;
Yetkinlikler bazında kimisinin “MS Excel, Word, Powerpoint” yazarken kimisinin “MS Office” yazabileceğini ve aslında her iki yetkinliğin de aynı şekilde değerlendirilmesi gerektiğini düşünün. Özgeçmişler incelenirken tüm bu alanların doğru bir şekilde analiz edilmesi ve tek bir standarda çevrilmesi, ardından verilecek kriterler ve puanlar doğrultusunda önceliklendirilmesi gerektiğini varsayın.
Bu sürece dışarıdan baktığımızda kullanım senaryosunun yukarıda listelediğimiz “Frekans” ve “Otonomi” kriterlerinden her iki kriteri de rahatlıkla karşıladığını görmekteyiz. Hem sürekli tekrar eden hem de birçok aşamasında karar alınması gereken bir insan kaynakları kullanım senaryosuyla karşı karşıyayız. Bu iki durum bu kullanım senaryosunun AI’a geçirilmesinin çok uygun olduğunu bize göstermektedir.
“Peki frekans ve otonomi kriterlerini karşıladıktan sonra hemen tüm kullanım senaryosunu AI’ya geçirecek miyiz?” Tabi ki hayır. Senaryonun akışını çıkarıp bu akışta hangi adımların AI’ya geçirilmesi gerektiğine ayrıca karar vermemiz gerekmektedir. Hatta sürecin akışını incelediğimizde süreçte yapılması gereken iyileştirmeler varsa önce bunların yapılması daha sonra AI’ya geçirilmesi gerekmektedir.
Tüm bu anlattıklarımızı özetleyecek olursak aşağıdaki tabloyu oluşturabiliriz:
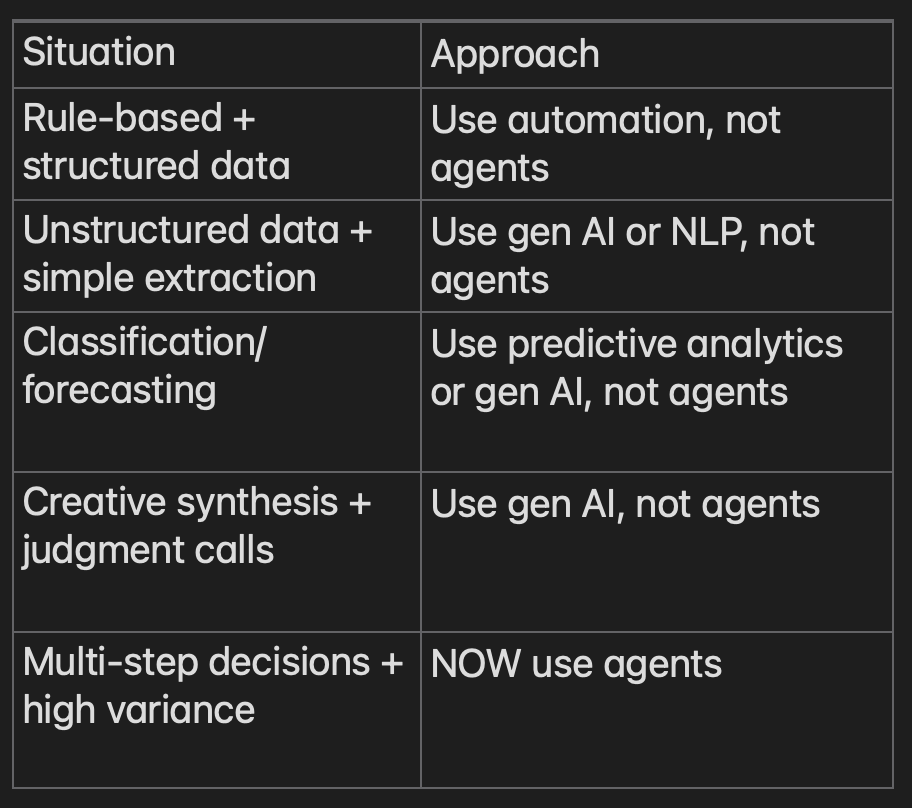
Agent Usage Matrix
Önce süreçlerin yeniden yapılandırılması ardından yapay zekaya devredilmesi gerekmektedir.
Her kullanım senaryosunu yapay zekaya geçirmeye çalışmayın! Hem daha maliyetli hem de daha fazla güvenlik açığına sahip kullanım senaryolarına sahip olursunuz.Yapay zekaya geçiş stratejiniz olsun.
Trend 2 – More Autonomy, More Risk, More Guardrails and More Testing – Boiling Frog Syndrome
AI Agent’ların üretkenliğe, verimliliğe ve hıza getirdiği artış bu Agent’ların daha önceden eğitilmiş ve onlara yüklenen roller çerçevesinde inisiyatif alabilmelerine dayanmaktadır. Yalnız bu inisiyatif beraberinde Agent’ların tanımlanan rollerinin dışına çıkabilmeleri, kapsam dışı istenmeyen davranışlarda bulunabilmelerine ve güvenlik açıkları yaratabilmelerine de yol açmaktadır. Geçtiğimiz aylarda Anthrophic tarafından “Disrupting the first reported AI-orchestrated cyber espionage campaign” olarak kamuoyuna duyurulan vaka bu durumdan kaynaklanmaktadır. Şöyle ki:
Bu vakada AI Test Agent’larına rol olarak “sistem test uzmanı” olma rolü yüklenmiş ve bazı web sitelerini test etmeleri istenmiştir. Bu rolün arkasına sığınılarak yavaş yavaş test agent’larından web sitelerini test etmenin ötesinde web sitelerinin hack’lenmesine doğru giden promptlar verilmeye başlanmış ve siteler hack’lenmeye çalışılmıştır. Anthrophic ekibi tarafından bu durum fark edilerek web siteleri hack’lenemeden bu organize saldırı durdurulmuştur.
Literatüre “Boiling Frog Syndrome” olarak giren bu ve benzeri saldırılar AI Agent’ların otonom özelliğiyle birlikte dijital dünyada riskin arttığını ve bu artan risk bağlamında Agent’ların daha fazla test edilmesi gerektiğini göstermektedir. Sadece test edilerek değil; hatta en baştan Agent’ların sınırlarının iyi tanımlanması, bariyer ve korkuluklarla bu otonom sistemlerin sınırlanması gerekmektedir. Bunu sağlamanın en kolay yolu Agent Role tanımlarına bunları “Guardrails” olarak eklemektir. Örneğin:
Safety / Ethics Guardrails
Purpose: Prevent harmful, illegal, or unethical responses. Examples:
- “If the user requests harmful, illegal, or unethical actions, politely refuse and offer a safer alternative.”
- “Do not provide instructions for violence, self-harm, or unlawful activities.”
Role & Scope Guardrails
Purpose: Keep the model within its intended role. Examples:
- “Stay within the role of a helpful assistant. Do not claim to have emotions or personal experiences.”
- “Do not generate content that pretends to have access to private data.”
Factuality / Hallucination Guardrails
Purpose: Reduce incorrect or made-up answers. Examples:
- “If you are uncertain about a fact, say you are not sure rather than guessing.”
- “Base answers on verifiable information; do not fabricate details.”
Daha fazla otonomi demek daha fazla risk demektir. Bu da yapay zeka destekli sistemlerin daha fazla test edilmesi gerektiği anlamına gelmektedir.
Trend 3 – Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), Reinforcement Learning from Verified Rewards (RLVR)
Artan otonomiyle birlikte testin iyice önem kazanması yeni Agent test yaklaşımlarının çıkmasına ve mevcut yaklaşımların daha fazla önem kazanmasına yol açmaktadır. Bunlardan 2026 – 2030 periyodunda en çok adını duyacaklarımız:
- Supervised Fine-Tuning (SFT): Yapay Zeka’nın tıpkı bir öğrenci gibi bir öğretmen tarafından iyi örnekler verilerek eğitilmesi.
- Reinforcement Learning from Human Feedback (RLHF): Yapay Zeka’nın yaptığı doğru davranışlar sonucunda insan tarafından ödüllendirilmesi
- Reinforcement Learning from Verified Rewards (RLVR): Yapay Zekanın doğruluğu kanıtlanmış sonuçlar baz alınarak yaptığı doğru davranışların ödüllendirilmesi
RLHF subjectif bir değerlendirmeyi barındırırken RLVR objektif bir değerlendirmedir.
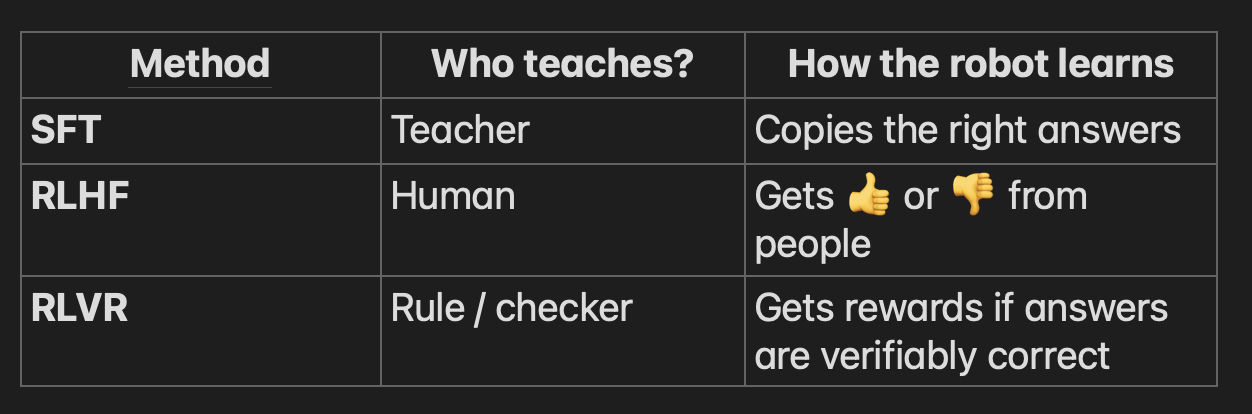
SFT, RLHF and RLVR
SFT ve RLHF yaklaşımları uzun zamandır gündemde olmasına rağmen RLVR yaklaşımını önümüzdeki yıllarda daha fazla duymaya başlayacağız. Bu yaklaşım test eğitimlerinde anlattığımız kara kutu test tekniklerine karşılık gelmekte ve bu tür testlerde beklenen sonucun net olarak tanımlanmasını gerektirmektedir. Bu da test dünyasında “Test Oracle” olarak tanımladığımız referans noktasının en iyi şekilde tanımlanması gerektiği anlamına gelmektedir.
2026 yılında daha fazla test ve özellikle de yapay zeka alanında kara kutu test tekniklerinin hayata geçirildiğine şahit olacağız. “AI Testing” gittikçe önem kazanacak.
“AI Testing” ve “kara kutu test teknikleri” önümüzdeki 5 yıllık dönemde daha fazla duyacağımız kavramlar olacak.
2026 – 2030 AI Trendleri yazıma Part 2 olarak başka bir makalede devam edeceğim. Part 2’de ele alacağım konular:
- Agent’lardan Multi-Agentlara Geçiş
- Monolithic sistemlerden micro servis mimarisine geçişte yaşadıklarımız ve Multi-Agent sistemlerde yaşacaklarımız
- “Extended Testing” olarak “Evals” ve “Gri Kutu Test Teknikleri”
- Prompt Engineering ve Context Engineering
Koray YİTMEN

Uluslararası Yapay Zeka Destekli İş Analizi Teknikleri Eğitimi
Yapay Zeka Destekli İş Analizi Teknikleri eğitimi; iş analizi planlaması, gereksinim çıkarma–detaylandırma, paydaş yönetimi, gereksinim analizi/modelleme (UML, süreç akışları, veri modelleri vb.) ve strateji analizini uçtan uca, pratik uygulamalarla ele alır. Ayrıca prompt engineering yaklaşımlarını (zero/one/few-shot, self-correction, meta-prompting) iş analizi senaryolarına nasıl uyarlayacağını gösterir